Unlocking the Magic of Large Language Models (LLMs): A Simple Guide for Curious Minds
Imagine having a super‑smart friend who has read millions of books and can chat with you about almost anything. Sounds amazing, right? That’s essentially what a Large Language Model (LLM) is. It’s an advanced type of AI that learns how language works by studying enormous amounts of text—and today, even images, sounds, and videos.
In this guide, we’ll break down how LLMs are built and how they work, using everyday examples and easy analogies. Think of it as the story of how you might raise a very intelligent AI friend from scratch.
Building a Language Giant: How LLMs Are Made
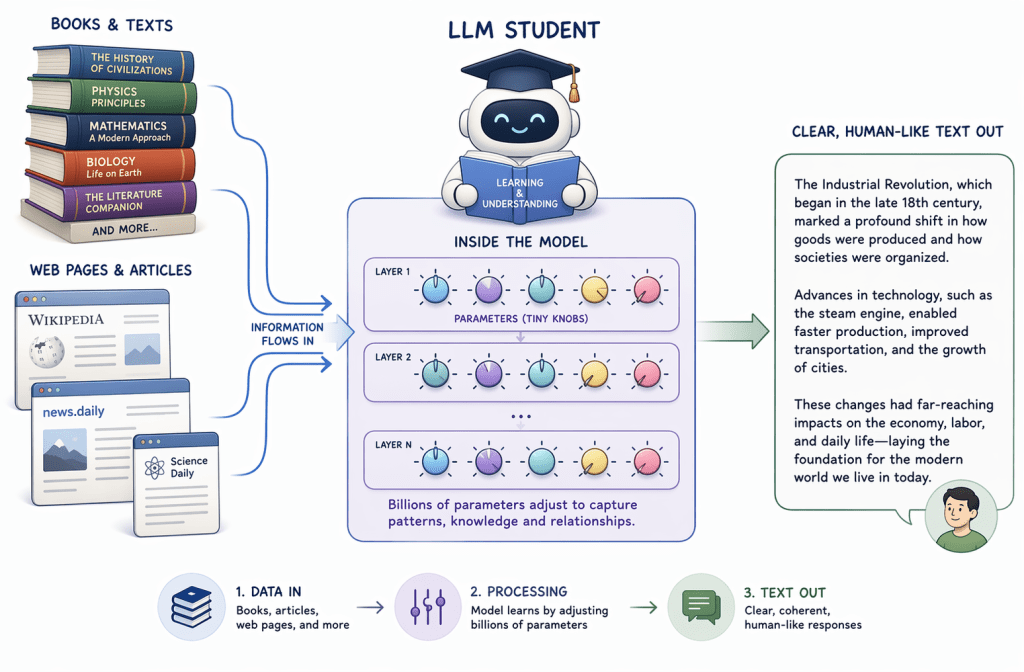
LLMs Learn by Reading… A LOT
Think about how you learn new things. You read books, listen to teachers, make mistakes, and improve over time. Training an LLM works in a surprisingly similar way.
An LLM is trained by feeding it billions (or even trillions) of words from books, websites, articles, and conversations. Behind the scenes, this learner is a neural network—a computer system inspired by the human brain. It has countless internal connections, called parameters, that slowly adjust as the model learns.
Learning Through Practice
During training, the model looks at a sentence and tries to predict what word should come next. If it gets it wrong, the system slightly adjusts those internal connections. Then it tries again. And again. And again—millions of times.
Over time, this process teaches the model patterns like grammar, meaning, and style. By constantly reading and correcting itself, the LLM becomes very good at producing natural‑sounding language.
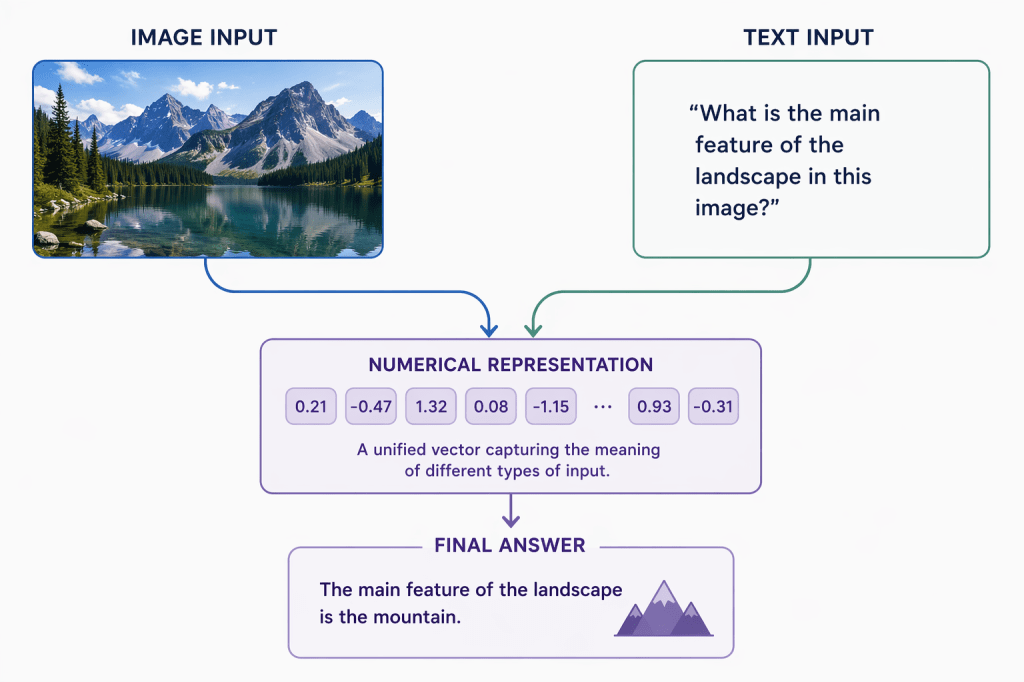
One Brain, Many Talents: How LLMs Handle Different Types of Data
Beyond Just Words
Early language models only worked with text. But modern LLMs are multimodal, meaning they can also understand images, audio, and even video.
So how can one model handle so many different things?
Everything Becomes Numbers
The secret is that computers convert all data into numbers. Text, images, sounds—everything gets translated into a numerical form the model can process.
For example:
- An image is split into small patches, and each patch becomes a set of numbers describing colors and shapes.
- Audio can be turned into sound waves or transcribed into text.
- Video is treated as a sequence of images plus audio.
Once everything is represented as numbers, the LLM can reason about it using the same internal machinery.
Think of a phone app that translates a photo of a sign from Spanish into English. First, it recognizes the letters in the image. Then it understands the text. Finally, it translates it. A multimodal LLM works in much the same way—by turning what it sees or hears into something it already knows how to process.
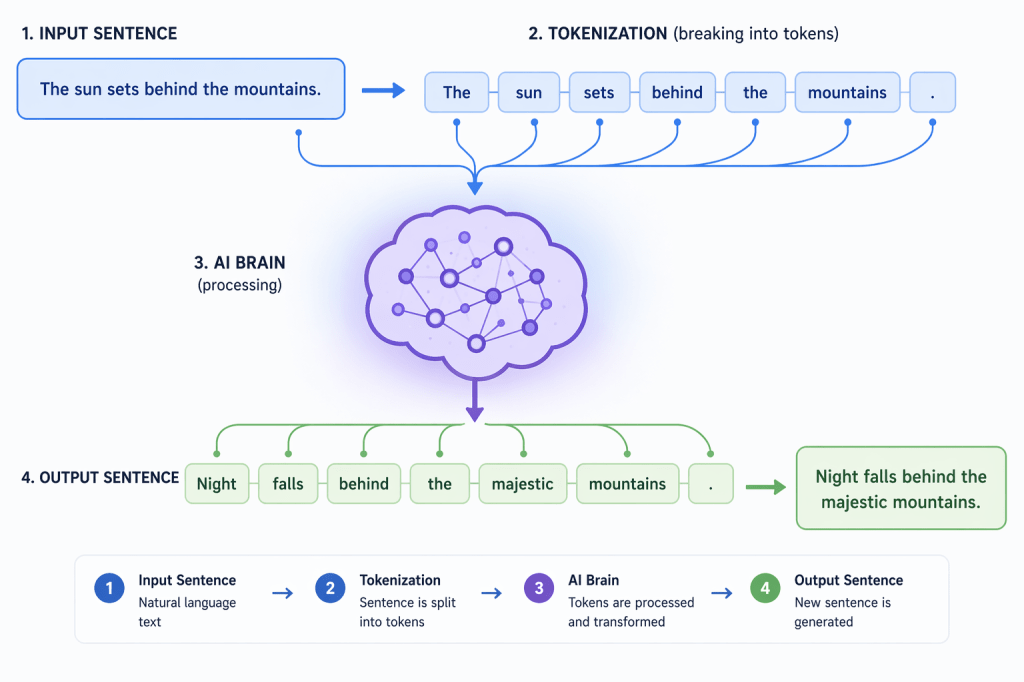
Tokens: The Tiny Building Blocks of Language
What Is a Token?
When you type a sentence, an LLM doesn’t see it as one big chunk. Instead, it breaks the text into tokens—small pieces that might be whole words, parts of words, or punctuation.
Think of tokens like LEGO bricks. Small pieces, when combined correctly, can build something much bigger and more meaningful.
For example, the sentence:
“I love AI!”
might be broken into tokens like: “I”, “ love”, “ AI”, and “!”
Why Tokens Matter
The model processes language one token at a time, always considering the surrounding context. Tokens are also how we measure limits. Every model has a maximum number of tokens it can handle at once—like a short‑term memory limit.
Putting together a sentence from tokens is like assembling a jigsaw puzzle. Each piece matters, and the full picture only makes sense once they’re all connected.
Inside the AI Brain: Parameters and Token Counts
Parameters: The Model’s “Experience”
If tokens are what the model reads and writes, parameters are what it remembers. Parameters are millions or billions of tiny internal values that store what the model has learned during training.
Tokens are the words on the page you’re writing right now. Parameters are the writing skills you’ve built over years of reading and practice.
You can think of parameters as experience. The more parameters a model has, the more subtle patterns it can capture—like knowing that “peanut butter” is often followed by “jelly.”
What Does “Token Count” Mean?
Token count can refer to two things:
- Training tokens: How much text the model saw while learning.
- Context window: How many tokens the model can consider at once when answering you.
The context window is like a whiteboard. A bigger board lets the model keep more information in mind, but it also requires more computing power.
Open‑Book Exams for AI: RAG and Vector Search
Even very smart models don’t always know the latest information. That’s where Retrieval‑Augmented Generation (RAG) comes in.
With RAG, the AI doesn’t rely only on what it learned during training. Instead, it can look up relevant information from external documents before answering.
How It Works?
Both documents and questions are converted into vectors—numerical representations of meaning. The system finds the documents most similar to your question and provides them to the model as extra context.
Imagine taking a test with your textbook open. You quickly flip to the right page, read a paragraph, and then answer the question in your own words. That’s exactly how RAG helps an LLM give better, more accurate answers.

Context: The LLM’s Short‑Term Memory
When you chat with an AI, it seems to remember what you said earlier. That’s because previous messages are included as context every time the model responds.
Internally, that context is turned into tokens and processed using attention mechanisms that help the model focus on what matters most.
Why Context Is Limited?
The model can only handle a fixed number of tokens at once. If a conversation gets too long, earlier details may drop out. That’s why summarizing or using RAG can be so helpful.
Why LLMs Need So Much Computing Power
Billions of Calculations, Every Second
Every word an LLM generates involves massive math operations. Training a model means doing these calculations over and over again on huge datasets.
That’s why GPUs are used. Unlike CPUs, which have a few powerful cores, GPUs have thousands of smaller cores that can work in parallel—perfect for AI workloads.
Baking one cookie is easy with one oven. Baking ten thousand cookies? You’ll need a whole bakery. GPUs are that bakery for AI—many ovens working together to get the job done fast.
Bringing It All Together
Large Language Models are built by reading enormous amounts of data, adjusting billions of internal parameters, and learning how language works piece by piece. They break information into tokens, rely on powerful hardware to process it all, and can even “look things up” using tools like RAG.
Think of an LLM as a highly trained storyteller and problem‑solver. It’s read more than any human ever could, works through ideas step by step, remembers recent context, and knows when to check a reference book.
What feels like magic is really the result of learning, practice, and a lot of computing power—and now, you know how it all fits together.
